





















The shift to skills-based hiring and the challenges that come with it
An April 2022 report by LinkedIn suggests a fundamental shift in candidate sourcing is underway. They found a 100% year-over-year increase in companies using skill filters to find relevant candidates for their open roles.
This skills-based candidate matching means that instead of doing a search based on years of experience or education, companies are looking for technical talent by entering their skills into a search engine.
Skills-based hiring practices greatly enlarge talent pools and reduce the cost of hiring as a result. But accurately matching skills remains a challenging technical task. The skills mentioned in a job description often do not precisely match a candidate’s resume.
In this article, we discuss how we’re solving this problem at Celential via a couple of common examples that we’ve seen by using state-of-the-art machine learning methods to power tech recruiting.
Unlocking the semantic similarity between skills with Node.js, Express.js, and Django
To break down how our approach works, let’s say you’re trying to hire a full-stack engineer with Node.js experience. So, you type Node.js into the search engine and are so disappointed by the results that you turn off your laptop.
But did you know that Express.js is a sub-framework that is used within Node.js? There are plenty of qualified engineers out there whose resumes or LinkedIn profiles list Express.js but not Node.js. We even found through our Talent Graph that 82% of Node.js engineers use Express.js.
When we source for Node.js engineers, our AI-based technology measures the semantic similarity between individual skills. It pulls up candidates with both direct Node.js experience and Express.js experience with just one query.
We do this via a quantitative, vector-based approach. A vector if you don’t remember Calculus, is a mathematical object with a collection of numbers. Each skill is assigned its own vector and has a collection of numerical values that our AI uses to relate that skill to other skills.
Solving the skills-based matching problem in practice
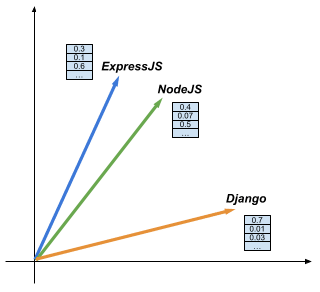
In our solution, both Node.js and Express.js are assigned 100 different numbers with values between 0 and 1.
The difference between these values will be quite small overall since these skills are highly related to each other. In comparison, the difference between the values for Node.js and Django will be larger. Both are web API frameworks, but Node.JS is a JavaScript framework, and Django is a Python framework.
Using this methodology, we built a taxonomy or classification system among millions of skills popular in the tech industry. We then apply Graph Neural Networks (GNNs) to that system which means the AI can perform inferences on the data described by the vector graphs.
If two skills are connected in the graph, the encoded vectors are closer to each other. Otherwise, they are distant from each other. Figure 1 represents this visually below:
Taking skills-matching a step further by encoding domain knowledge
Domain knowledge also matters when we create these vector representations. For example, default detection is a term from both finance and manufacturing.
In finance, it means the risk of loan default; in manufacturing, the application of computer vision to detect defects.
Any skill-based hiring technology needs to be sensitive to this ambiguity where the same term can mean different things depending on context. Otherwise, it runs the risk of suggesting loan analysts as candidates for manufacturing jobs.
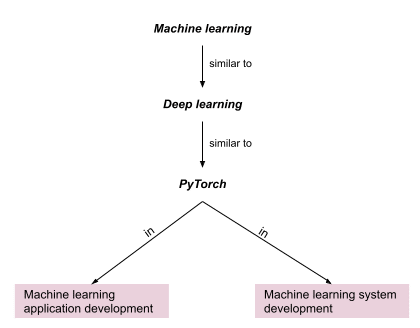
Even unambiguous skills can have different meanings in different contexts. Building a machine learning system with PyTorch is very different from building machine learning applications with PyTorch. Someone building machine learning systems with PyTorch has solid system-level programming experience while someone building machine learning applications with PyTorch has strong data science modeling capability.
Suggesting a systems engineer for a data science modeling role isn’t much more helpful than suggesting someone from a bank work at a factory.
How our graph neural networks encode domain information to remove skill ambiguity
To account for this ambiguity, we connect skills with each other and with their product domains. Our AI can automatically connect a skill with a product domain based on the relevant domain experience it found in their resume, LinkedIn profile, or other publicly available information.
It works by our GNNs encoding vectors to represent both which skills are related to each other and which product domains those skills belong to.
For skills like PyTorch, 50 of the 100 numbers could be compared to another skill while the rest correspond to a product domain. Figure 2 below provides an example of this.
Wrapping up: more to come on machine learning and skills matching!
Using vectors for skills-based hiring represents a huge improvement in candidate matching compared to more common keyword-based approaches, and even compared to some other machine learning models like TF-IDFs.
Nonetheless, there are still other important aspects of this problem beyond the scope of this article.
For instance, once you’ve determined that someone is proficient in a given skill, how do you determine their level of proficiency? We’ll have more posts that elaborate on how we address these challenges via advanced machine-learning technology to power our tech-sourcing solution.
Subscribe to our blog for more insights about candidate skills matching to boost your sourcing efforts.
Table of Contents


Submit a Comment